2.5. Analyse af input
Er et oversætterprogram et filter? På en måde ja. En bestemt slags input giver altid et bestemt output. Output er afhængigt af (ét) input.
Tag nu som eksempel følgende to små programmer. De vil, hvis vi oversætter dem til statisk linkede, strippede filer, være helt ens. I de færdige programmer vil der ikke være noget ord "alfa" eller "beta" - det er blot et midlertidigt navn for nummeret på den memory - celle, hvor oversætteren anbringer vores tal. Prøv selv med kommandoen strings prog1 .
/* prog1.c - lav om på variabelnavne og oversæt: gcc prog1.c -s -o prog1 */
int alfa 112233;
main(){ printf("min globale variabel har værdien %d\n", alfa); }
/* prog2.c ligner prog1 */
int beta 112233;
main()
{
printf("min globale variabel har værdien %d\n", beta);
}
Selv om vi ændrer variables navne og laver om på linjedeling, kommentarer mv. får vi nøjagtigt samme maskininstruktioner ud af det, med andre ord, der er en entydig bestemmelse af ouput ud fra input. Men for samme output kan vi altså have flere forskellige input.
Kan et program analysere input? Det kommer an på, hvad man mener med analyse. Hvis man forventer en forståelse, så nej, men hvis analysen giver sig udslag i, at en struktur i input oversættes til en anden struktur, så jo, så kan et program analysere input.
Der sker en transformering af input, og den er bestemt af regler. I en parser er det reglerne, som er de mest interessante. Når vi ønsker at bygge en oversætter, så skifter vores fokus fra de laveste, små input enheder, d.v.s. bogstaver og tal, til større enheder, sætninger, blokke og funktioner.
Der er mange teknikker til at skifte fokus fra de laveste inputenheder, characters og words, til højere niveauer, blokke mv. En af mere taknemmelige metoder er den rekusivt nedstigende parser, som opbygges af et hierarki af funktioner, hvor de øverste tager sig af de store linjer, og de nederste i call-hierarkiet tager sig af de mindste, syntaktiske enheder.
Den rekursivt nedstigende parser (recursive descent parser) er en attraktiv metode for både begynderen og den viderekomne programmør. Bjarne Stroustrup fortæller i sin bog "The Design and Evolution af C++" at han oprindeligt ville bruge en recursive descent parser til Cfront, den første C++ compiler. " [...] it is possible to write an efficient and reasonably nice recursive descent parser for C++. Several modern C++ compilers use recursive descent." Stroustrup[1], p. 69.
For begynderen er det imidlertid en stor mundfuld at forstå en fuld-skala rekursiv nedstignings parser, men det klares, som bekendt, ved at dele opgaven op i små bidder. Intet problem er så stort, at det ikke kan deles i flere mindre. Hvem har sagt det?
I de næste eksempler vil vi derfor opbygge en tag-parser efter terrasse-princippet, d.v.s. at vi lægger ud med at løse en beskeden del af opgaven. Først når den virker, kommer vi yderligere features på. Man er nødt til at skrive nogle simple inputfiler for at teste programmet, men det kan nu være ganske fornøjeligt at se, hvad der sker, når man "leger" med input.
2.5.1. En tag - parser
Når man skriver tekst i sgml format, så vil det være rart, at man kan få hjælp til at kontrollere sine tags. Det program, jade [1], som fremstiller html, postscript, pdf-filer etc.etc. ud fra vores kildetekst, skal selvfølgelig også kunne tjekke for, at man har anvendt tags på den rigtige måde. Men inden man kommer dertil, kan det somme tider være rart med et mindre program, som tjekker, at man har husket alle end-tags, og endnu bedre, et program, som kan formatere lidt på afsnit og indrykning, så kildeteksten er lettere at læse. Man kunne så fortsætte med at lave et program, som ville udskrive en formateret ascii udgave.
Et sådant program kunne for eksempel få flg. input:
<chapter><title>Dette er kapitel 1.</title> <para> Dette kapitel handler om de teknikker, som en programmør kan bruge til at analysere input. </para> </chapter>
Når vi har kørt input gennem vores tag-kontrolprogram, forventer vi, at output skal se ud nogenlunde som flg.:
<chapter>
<title> Dette er kapitel 1.
</title>
<para> Dette kapitel handler om de teknikker, som en programmør
kan bruge til at analysere input.
</para>
</chapter>
Hvis der mangler en end-tag, skal programmet komme med en fejlmeddelelse. Programmet kommer (forhåbentlig) til at ligne indent programmet, som forskønner C - kildetekst ved at sørge for systematisk indrykning og placering af kommentarer m.v. (se Afsnit A.3.)
Man kan diskutere detailler omkring formatering, men i første omgang vil vi blot have den simplest mulige løsning. Og ikke nok med det, den første version af programmet skal blot afprøve IO mekanismerne.
Hvis vi skal analysere tags, skal vi kunne se mindst et ord af gangen. Det er heldigvis meget nemt, idet vi kan nøjes med en linjebuffer. Et ord vil aldrig være delt hen over en linje. Orddelinger på grund af linjelængde forekommer ikke .
Vores linjebuffer skal være stor nok, selvfølgelig, og vores program skal reagere fornuftigt på buffer overflow, derfor bruger vi fgets(), som stopper, når bufferen er fuld.
For at se på det næste bogstav skriver vi en lille funktion, ch(), som blot returnerer det næste tegn i vores linjebuffer. Men når vi læser og fremrykker pointeren, så skal der selvfølgelig tjekkes på, om der er et gyldigt tegn forude, hvis der ikke er, kaldes fillbuf.
I stil med Eksempel 2-19 kan vi dog lige tilføje en lille feature til dette program, nemlig, at hver gang, der ses en kile, d.v.s. < ofte kaldet mindre-end tegnet, konverteres til en sgml-kode, "<". Det har vist sig at være et nyttigt program, når man vil inkludere for eksempel en stump af et C-program i en sgml kildetekst.
Eksempel 2-22. En tag - parser, forstadium
/* sgmlfmt_pre1.c Forstadium til mini program, som tjekker balancen i
* sgml tags. I den nuværende skikkelse kan programmet erstatte
* alle "mindre-end" tegn med sgml-koden for dette, altså < -
* så det kan såmænd bruges til at filtrere C-programmer, der
* skal includeres i en sgml-tekst. */
#include <stdio.h>
#include <string.h>
#include <strings.h>
#include <errno.h>
#include <error.h>
int status;
int eofile; /* global end of file */
#define MAXB 8000
char buf[MAXB];
int endbuf;
int bufindex;
int init();
int fillbuf();
int ch();
int gch();
int parse();
int main()
{
if (init() == 0)
return 1;
while (!eofile) {
if (ch() != '<')
putchar(gch());
else {
printf("<");
gch(); /* discard character '<' */
}
}
return 0;
}
int init()
{
/* insert initialization of global vars here */
return fillbuf();
}
int fillbuf()
{
char *rv;
if (!(rv = fgets(buf, MAXB, stdin)))
strcpy(buf, "");
endbuf = strlen(buf);
bufindex = 0;
return (int) rv;
}
/* ch() returnerer den næste character i input stream *men* læser
* ikke, og ændrer ikke noget i den eksisterende buffer. Det
* svarer til at spørge "Hvad er det næste input tegn, hvis vi nu
* gad gå videre?!"
*/
int ch()
{
return buf[bufindex];
}
int nch()
{
return buf[bufindex + 1];
}
/* Hvis vi altid vil kunne se mere end én character fremefter, må
* vi udskifte gch() og fillbuf() funktionerne, således at de
* tjekker, hvor meget er der i bufferen, og hvis der er for få
* (mindre end ønsket) skal de efterfylde bufferen og justere
* pointere.
* Det søde ved denne implementering er imidlertid, at vi altid
* har én character lookahead (garanteret), men hvis vi ser på et
* ord, kan vi se hele resten af ordet, fordi et ord ikke kan
* krydse en linjedeling.
*/
/* gch() returnerer samme som ch() men flytter pointeren en plads
* frem. Hvis vi ved fremadrykning rammer end of line (en
* nul-byte) må vi fylde bufferen, så ch() næste gang har et tegn
* at kigge på.
*/
int gch()
{
int c;
if (nch() == 0) {
c = ch();
if (!fillbuf()) {
eofile = 1; /* will take effect for the next char */
}
return c;
}
return buf[bufindex++];
}
Programmets main kunne såmænd udmærket nøjes med at benytte getchar og putchar. Der er ikke noget vundet i dette program ved at benytte en særlig input mekanisme. Men det, som er det egentlige formål med programmet, er jo også at bygge grundbestanddelen til et andet. Det er "terrasse 1", og hvis det virker og kopierer input til output (med undtagelse af < tegn), så er grunden lagt til næste udgave af programmet, som blot skal tjekke, om en tekst har balancerede tags.
Funktionerne ch() og gch() administrerer bufferen. Andre funktioner i programmet kigger ikke direkte i den globale variabel "buf[MAXB]". Det kunne være en privat variabel, som lå i et IO-modul. (Prøv at ændre programmet på den måde.)
En af de ting, der drillede ved konstruktionen af programmet, var, at gch() skal fylde bufferen - den er jo ansvarlig, klart nok, for at der er en næste byte at læse. gch() er den eneste, som kalder filbuf. Men hvornår skal den fylde bufferen? Hvis buffer indexet peger på newline eller en streng-slutning (null-byte), så kunne det være signal til at fylde bufferen op. Da det alligevel blot er en newline, så kunne man smide den væk.
Men det er ikke en god idé (her) - for at det skal kunne lade sig gøre at gengive linjeskift i for eksempel litteral tekst er det nødvendigt at lade gch() kigge en byte fremad.
Så man skal altså huske at "gemme" den sidste byte i bufferen i en variabel, og derefter fyldes bufferen igen.
Derved opstår der et andet problem. Hvornår rammer man end of file. Hvis caller af gch() tester på end of file INDEN han bruger den character, han har fået med gch(), så vil der - i denne version - gå kage i systemet.
I dette lille program er det imidlertid overskueligt at huske, at man skal anvende returværdien fra gch() inden man tester for end of file (eller teste for end of file inden man kalder gch()).
Input mekanismen, som den er præsenteret her, er en forsimplet udgave af input mekanismen i small-C compileren, se Afsnit 4.3.
Programmet anvender IKKE pointere. I stedet indexeres array'et med variabelen bufindex.
2.5.2. Tjek balancering af tags
I den næste version af tag-parseren, tagbal01.c, kan man se, hvordan input mekanismen er bevaret. Programmet er ikke gengivet her i sin fulde udstrækning, men ligger som en fil i kataloget med eksempler.
Opgaven består denne gang i at skrive et program, som kan læse en tag og "huske den", indtil vi kommer frem til næste tag. Hvis den næste tag er en end-tag (med skråstreg, for eksempel </chapter>) så skal teksten efter skråstregen være samme ord, som vores start tag. Hvis det er en ny start tag, fx. <section1>, så skal den accepteres, og programmet leder nu efter en end-tag for section1.
Vi kan beskrive flow'et på flg. måde:
så længe der er en tag <navn>
hvis den næste tag er en start tag
kald rekursivt
ellers
hvis det ikke er en end-tag, som matcher <navn>
meld fejl
ellers returnér ok
Når vi har fundet en end-tag, som matcher start-taggen, skal vores funktion altså returnere true (eller ok). Denne simple version skriver m.a.o. ikke noget output.
Den funktion, som skal klare chapter-/chapter, kan selvfølgelig være lavet sådan, at den kun leder efter chapter. Men da mekanismen er den samme, når vi leder efter section eller para, så er det nok bedre at lade vores funktion acceptere et hvilket som helst tag navn, og så gemme det i en character buffer. Derved kan vi bruge den samme mekanisme for både chapter, section1 og alle mulige andre.
Programmet kunne i simplest mulige form simpelt hen se sådan ud:
scan_for_tags()
{
char newbuffer[MAXT];
int j = 0;
if (ch() != '<')
parse_error("Need tag here\n");
// ok, der er en tag
gch();
if (ch == '/')
parse_error("Cannot have end tag here\n");
while ( ch() != '>' )
newbuffer[j++] = gch();
// Nu skipper vi al almindelig tekst indtil næste tag.
while (ch() != '<')
gch();
// Nu stoler vi på, at vi kan se 2 characters frem
if (!match("</")) {
// ikke en endtag
scan_for_tags(); // tag lige alle indskudte tags her!
}
// Ok, denne gang er det en end-tag:
gch();gch(); // nu er vi fremme ved tag-navnet
if (match(newbuffer)) {
if (gch() != '>')
parse_error("Need end-angle here\n");
else
return 1; // ok.
}
parse_error("tag-name non-match\n");
// parse_error returnerer ikke, så vi kommer aldrig her, men
// vil gerne gøre compileren glad...
return 0;
}
Ovenstående funktion kalder sig selv, hvis den ser en ny start-tag efter at den er gået i gang med at lede efter en end-tag.
Det er en simpel version af rekursiv nedstigning. Der er flere forskellige ting, denne her parser ikke kan klare. Hvis man skriver sin tag hen over en newline (hvilket er lovligt) så vil parseren includere newline i tag-navnet. I det hele taget tager den alt, bogstavelig taget alt, inden slut vinkelen, og gemmer det som et tag-navn. Endvidere tjekker den ikke for buffer overflow, men det kunne man nemt indføje. Den er ikke desto mindre en god demonstration af, hvordan rekursionen kan gøre det muligt for os at håndtere mange forskellige slags input. Hvis der er 17 tags inden i hinanden, fint. Hvis vi først lægger 5 inden i hinanden og bagefter får 2 endtags og så igen en start-tag, fint, så klarer funktionen også at validere den slags input.
Det vil være en god øvelse at afprøve ovenstående. Det findes ikke som en fil i eksemplerne. Man kan klippe funktionen her og indsætte den i en kopi af sgmlfmt_pre1.c -- eller man kunne skrive hele programmet for at få lidt øvelse.
2.5.3. Any-tag
Lad os forfine ideen fra foregående eksempel. I stedet for at lede efter start-tag tegnet, så overlader vi alt det beskidte arbejde (inclusive håndtering af linjeskift og spaces) til en funktion, som vi vil kalde anytag(). Derved bliver programmet meget lettere at læse.
Hvis funktionen anytag() ser en tag, fint, så gemmer den navnet i den buffer, den har fået og returnerer true. Hvis den ikke finder en tag, så returnerer den blot false. Det må vores parser så benytte sig af. Her kommer pseudo-koden:
hvis der er en ny starttag <navn>
så længe der er mere input
lad tekst data passere
hvis der er en end-tag
begynd forfra (d.v.s. se efter en ny starttag)
ellers skift niveau (d.v.s. rekursivt kald)
ellers
returner false
Opmærksomheden kan nu koncentrere sig om, hvordan man scanner for en tag med tilhørende slut-tag. Ovenstående pseudo-kode svarer til funktionen parse_level1. Navnet giver en forudanelse om, at man senere kunne have forskellige levels i parseren, som hver især er udtryk for, at der gælder forskellige regler for forskellige tags. Men her bliver de alle behandlet ens. Der er ikke nogen regler for, hvilke tags der må være inde mellem andre tags. Programmet skal blot kunne tjekke, at der efter en <tag>, kommer en </tag> (altså en slut-tag af samme type) senere, evt, efter nogle andre, indskudte (nestede) tags og med "tekst data" både før og efter.
For at få tag'en analyseret kalder parse_level1 den dertil indrettede funktion anytag(), som afleverer navnet eller keywordet på taggen i den buffer, som den får adressen på. Parse_level1 gemmer navnet på taggen for senere at kontrollere, at den tilsvarende end-tag har samme navn.
parse_level1 accepterer nu ord ved at kalde getword. Typisk ville det være efter en para-tag. Når getword støder ind i et '<'-tegn stopper den. Når den returnerer 0 er det fordi den er stødt ind i en ny tag (eller end-tag) -- eller fordi der ikke er mere input.
Nu kommer det spændende! Hvad må der komme efter? På dette sted i input kan der komme en end-tag eller en ny tag. Hvis det er en end tag, har vi sluttet ringen og bør gå et niveau ned og se, om der er mere tekst efter end-taggen. Det gøres ved at breake og hvis der ikke kommer en ny tag returneres fra parse_level1.
Hvis den nu har kaldt sig selv, så er vi ikke på det yderste niveau. Der returneres til stedet lige efter det rekursive call, og programmet begynder forfra på while-loop(2). Herved vil det igen ser efter med getword, om der er "tekst-data". Men altså på et niveau lavere. (Det kan ses på indrykningerne i output).
Her kommer det centrale sted i programmet tagbal01.c:
Eksempel 2-23. Tjek om sgml-tags balancerer
#define MAXT 80
int parse_level1()
{
char tagname[MAXT];
while (!eofile) { /*(1)*/
if (!anytag(tagname)) {
return 0;
}
while (!eofile) { /*(2)*/
while (getword()) /*(3)*/
putword();
if (have_endtag(tagname))
break;
(void) parse_level1(); /* nested tags */
}
blanks();
}
return 1;
}
Nøglen til forståelse er at følge flowet og forestille sig input i stil med flg.: <sect1> <para> text-text <emphasis> _text_ </emphasis> text2 <emphasis> !text3! </emphasis> text4 </para></sect1>
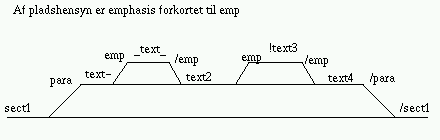
Indsæt printf() statements forskellige steder i programmet og afprøv med små input filer. Sæt ord mellem para-tags. Prøv at undersøge, hvad der sker, hvis man ikke ignorerer return value i det rekursive kald til parse_level1().
Det vil være en god øvelse at tjekke, om der i programmet er mulighed for buffer overflow nogen steder.
2.5.4. Skelnen mellem tagtyper
tagbal02.c er bygget op nøjagtigt som tagbal01.c, men kan skelne mellem et par grundlæggende typer sgml-tags, nemlig comment, programlisting og literal. Den kan også anvende en speciel regel for programlisting og literal, tekst data imellem dem bliver leveret videre som den er, uden formatering eller ombrydning af linjer.
Eksempel 2-24. Udvidelse af parse-level1 med kendte tag-typer
int parse_level1()
{
char tagname[MAXT];
while (!eofile) {
blanks();
if (comment()) {
continue;
}
if (programlisting(tagname) || litt(tagname))
(void) do_litteral(tagname);
else if (!anytag(tagname))
return 0;
while (!eofile) {
while (getword())
putword();
if (have_endtag(tagname))
break;
(void) parse_level1(); /* nested tags */
}
blanks();
}
return 1;
}
Find funktionen parse_level1() og sammenlign med tagbal01.c. Nu er det ikke kun anytag, den kalder. Der er kommet special-funktioner til, som håndterer henholdsvis kommentarer, programlisting og litteral-tags. De er bygget op som anytag(), de returnerer false, hvis de ikke ser den tag type, som de er "sendt ud for at lede efter".
Klart nok må man så vente med at kalde anytag() til efter at de andre har fået chancen. Anytag() accepterer jo hvad som helst, der er en tag, så andre funktioner ville overhovedet ikke blive kaldt.
I en sgml parser kunne anytag() benytte en liste over tilladte tag navne; hvis en tag ikke stod i denne tabel, så var den ulovlig og programmet skulle stoppe med en fejlmeddelelse.
Et eksempel på kørsel af programmet, med en lidt forsimplet form for sgml-tags, kommer her.
dax@pluto: cat lidt.sgml
<chapter>
<sect1 id="tag_balance_tjekk">
<para>
Dette er
en prøvetekst.
</para>
<para>
mere tekst i ny paragraf
<footnote><para>
fodnote text kommer her.
</para> </footnote>
</para>
<programlisting>
while (++x < 10)
printf("Hello!\n");
</programlisting>
</sect1>
</chapter>
<!-- her kommer en kommentar -->
<azerty> Programmet klager ikke over en ulovlig tag.
</azerty>
dax@pluto: tagbal02 < lidt.sgml
<chapter>
<sect1 id="tag_balance_tjekk">
<para> Dette er en prøvetekst.
</para>
<para> mere tekst i ny paragraf
<footnote>
<para> fodnote text kommer her.
</para>
</footnote>
</para>
<programlisting>
while (++x < 10)
printf("Hello!\n");
</programlisting>
</sect1>
</chapter>
<!-- her kommer en kommentar -->
<azerty> Programmet klager ikke over en ulovlig tag.
</azerty>
dax@pluto:
Som det kan ses, beklager programmet sig ikke over, at der forekommer en ulovlig tag sidst i input. Programmet formaterer teksten, ikke så avanceret, men nyttigt nok, og foretager indrykning, hver gang der forekommer en tag er inde i en anden tag.
Hele programmet ligger som en fil i eksempelsamlingen, tagbal02.c.
Forslag til øvelse: Dette program kan med få modifikationer benyttes til at trække teksten ud af en sgml fil, og endda i en læselig formatering. Overvej, hvilke forbedringer, som kunne gøre denne tekstudtrækning - ascii formatering - endnu mere nyttig. (Jeg har ikke nogen løsning på denne øvelse - endnu!)
2.5.5. Tilstandsvariabel
Det er lidt af en provokation at kalde det næste program for et filter. Man kunne lige så godt kalde det en parser eller en tilstandsmaskine. Det er også en lexical analyzer. Men strengt taget er det også et filter. Der kommer noget input ind fra (kun) én kilde, og afhængigt af dette spytter programmet noget andet ud. Der er en årsagssammenhæng fra input til output. Det samme input vil altid give det samme output. Men det går kun den ene vej. Et bestemt output kan produceres af mange forskellige slags input.
I modsætning til de tidligere eksempler er der i dette eksempel en variabel, som husker den tilstand, vi er i.
Og hvad er det så for et program? Et WORD count filter! Input er tekst, og output er blot antallet af ord. Provokation! Er det virkelig et filter? Ja, for det opfylder jo alle de ovenstående krav. Det sluger input fra en kilde og omformer det til output, som, ok, kan være det samme for flere forskellige slags input, men samme input -- altid samme output. Vi baserer vores program på en lille bemærkning i Kernighan & Ritchies version af word countEksempel 2-27: Nemlig at begrebet "et ord" kan forfines, så man kan skelne mellem rigtige ord og tal, tegnsætning og lignende.
Hvis du ikke kender det grundlæggende wordcount program, så er if sætningerne i dette program næsten uforståelige. Se derfor Eksempel 2-27 hvis du ikke kender det.
Programmet her starter med at være i en tilstand, som vi kalder HVID. Når vi ikke har læst noget, så må vi være på HVIDt papir.
Vi skal benytte en variabel til at huske denne tilstand, og vi kalder den status.
For at gøre det lettere at læse programmet, lader vi denne variabel være af enum - typen. Så kan en god oversætter holde styr på, om vi tilskriver den andet end symbolske navne som tilhører typen. Dog kun med warnings.
Eksempel 2-25. Ord - tælling
/*file ordtael.c */
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
typedef long long _int64;
/* taellere: char, words, num, andet, lines */
_int64 nc, nw, nn, na, nl;
enum status_t { HVID, ALFA, TAL, PUNC };
enum status_t status;
int main()
{
int c;
while ( (c=getchar()) != EOF) {
++nc;
if (c == '\n')
+nl;
if (ispunct(c))
++na;
if (isspace(c)) {
status = HVID;
} else { /*(1)*/
if (status == HVID || status == PUNC) {
if (isalpha(c)) { /*(2)*/
status = ALFA;
++nw;
} else if (isdigit(c)) { /*(3)*/
status = TAL;
++nn;
}
} else if (ispunct(c)) { /*(4)*/
status = PUNC;
}
}
}
printf("Antal: chr %Ld, ord: %Ld, tal %Ld, andet %Ld, lin. %Ld\n",
nc, nw, nn, na, nl);
return 0;
}
/* OBS: Der er lidt flere braces i ovenstående eksempel end
* nødvendigt, det er i håb om bedre læselighed.
*/
/* end of file ordtael.c */
Det er statusvariabelen, som "husker", om vi er inde i et ord eller ej. Og det er statusvariablen, som gør det muligt at skrive programmet på en forholdsvis læselig måde Hvis opgaven imidlertid blev forsøgt løst uden statusvariabel, så ville der komme endnu flere if-sætninger. Inde i dem måtte man så lave nogle loops med læsning af input, så længe vi er i et ord. Og så bliver programmet fuldstændigt barokt kompliceret, prøv selv!.
(1) Hvis vi lige er har fat i noget, der er "ikke-space" og tilstanden stadig siger HVID, så betyder det jo, at vores tilstand lige netop nu ændrer sig. Derfor bør vi tælle antal af ord (eller tal, tegnsætning, etc.) op.
(2) Som ord tæller vi alt, hvad der begynder med bogstaver.
(3) Som tal tæller vi alt, hvad der begynder med cifre.
(4) Læg mærke til, at ETHVERT skilletegn udløser en tilstandsændring til PUNC, fordi denne sætning er sideordnet med den if, der står lige efter den (1) mærkede else.
Hvis indrykningen i dette program bliver smadret, så er det komplet umuligt at forstå meningen med det.
Programmet er udmærket til at danne sig et skøn over forholdet mellem tal og ord i en artikel.
Ordtael.c er i stand til at taelle et funktionskald som f.eks. qwerty(6000) som et ord, et tal og 2 andre tegn. Til gengæld tæller det 123Mb som et tal (uden ord).
MITPROMPT$ ordtael <<STOP hej(42); STOP Antal: chr 9, ord: 1, tal 1, andet 3, lin. 1
Hvis vi skal forfine programmet, så er det klogt at skifte taktik. Løsningen ovenfor skalerer ikke godt, når antallet af tilstande vokser, og input indeholder mange flere kategorier. En tilstandstabel kan bedre håndtere opgaven. Se Kapitel 4.