12.2. Nagios
Nagios er et overvågningsværktøj der kontrollere om alle services på alle maskiner køre. En typisk brug er at sætte Nagios op til at overvåge et antal maskiner der er forbundet i netværk, og administratorene af disse maskiner bliver så alarmeret når der er noget galt med de services de har ansvaret for. Det er ganske få ting der skal sættes op for at få det hele til at virke, men følger man den vedlagte dokumentation i Nagios, er det ikke sikkert man kommer helt i mål. Som det fremgår af Nagios-manualen: "Relax - its going to take some time." - så syntes forfatteren at det skal være meget besværligt at få begyndt med et Nagios-system. Men med de eksempler der følger med dette kapitel du læser på nu, samt beskrivelsen her, så skulle du gerne have en simpel kørende installation igang på ca. time hvis du er sådan en almindelig habil systemadministrator.
Nagios er opbygget som en central enhed der kontakter de andre maskiner og henter status fra dem. Nogle services såsom HTTP, SMTP og SSH kan checkes direkte fra Nagios maskinen selv fordi de anvender en åben port. Status vedrørende diskplads og andre interne services skal kontroleres ved at køre et program på den pågældende maskine. Programmet der skal køres på klient-maskinen hedder NRPE.
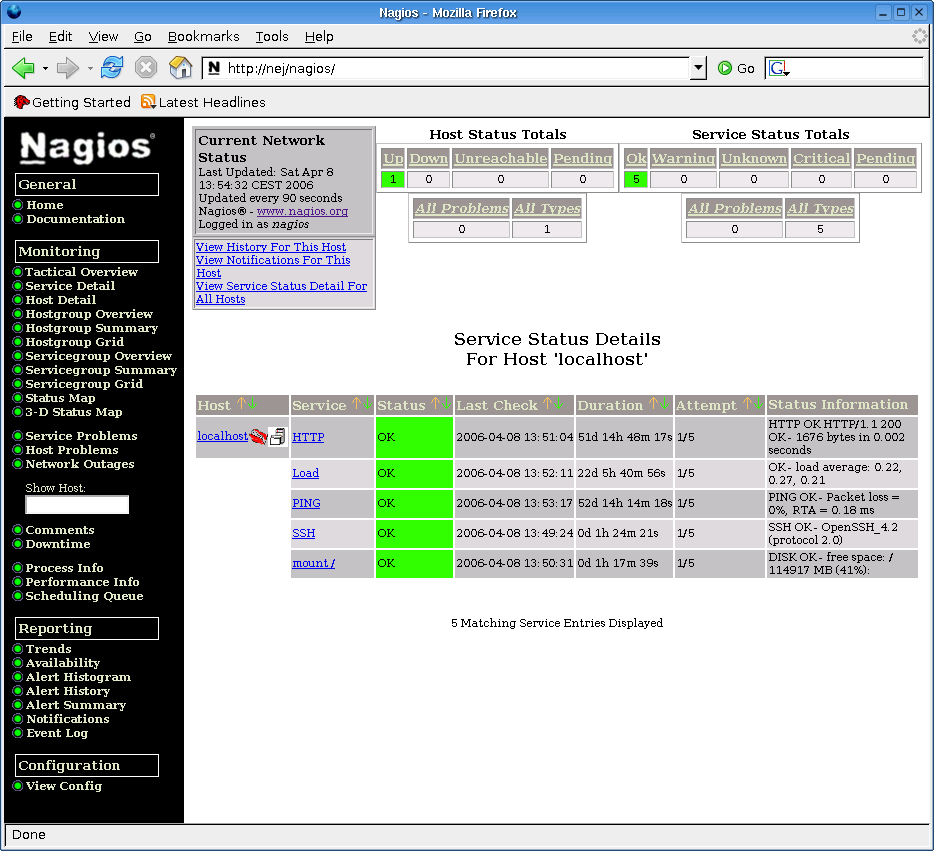
Som supplement til denne beskrivelse er der nogle konfigurationsscript du kan bruge som udgangspunkt. Sådanne start-script burde som udgangspunkt have været med i standardpakken, men det er de ikke. Disse ekstra-scripts kan downloades fra http://www.linuxbog.dk/admin/eksempler/etc/nagios Når de er blevet installeret vil du få et skærmbillede der ligner nedenstående.
Følgende programpakker skal downloades for at kunne komme igang.
-
http://www.nagios.org/download/ Nagios: nagios-2*.tar.gz er selve programmet der skal køre på serveren og det program der indhenter informationer fra de andre maskiner.
-
nagiosplug.sourceforge.net Nagios plugins: nagios-plugins-1*.tar.gz er en samling af små programstumper der checker de enkelte services. Eksempelvis findes programmet check_http i den pakke. og det anvendes til at checke web-serveren på en fjern maskine. Du skal have denne pakke installeret for at kunne bruge Nagios til noget. Det kan så undre at den ikke er en del af standardpakken.
-
http://www.nagios.org/download/ NRPE: nrpe-*.tar.gz anvendes for at kontrollere ting der foregår lokalt på en fjern-maskine. Vil man holde øje med fx diskplads, skal man bruge NRPE-pakken på klient-maskinen.
12.2.1. Installation
I beskrivelsen her er valgt at installere fra grundpakken og ikke bruge et pakkeformat der passer til en specifik distribution. Grundinstallationen er baseret på BSD's måde at placere filerne på, så det er en værre rodebunke at hitte rundt i, når man er vant til Linux. Herunder er vist en måde som filerne kan lægges ud på. Vigtigst er det at du kan finde konfigurationsfilerne i /etc/nagios, men de andre subdir er nu også rare at vide hvor ligger. Kør først en configure, efterfulgt af make og make fullinstall.
[tyge@hven ~]$ [ -z "`grep ^nagios: /etc/group`" ] && groupadd nagios
[tyge@hven ~]$ [ -z "`grep ^nagios: /etc/passwd`" ] && useradd -c "Nagios" -g nagios -d /var/www/nagios/html -s /bin/bash nagios
[tyge@hven ~]$ cd nagios-2.0
[tyge@hven nagios-2.0]$ ./configure \
--sysconfdir=/etc/nagios \
--bindir=/usr/bin \
--libexecdir=/usr/libexec/nagios \
--sbindir=/var/www/nagios/cgi-bin \
--datadir=/var/www/nagios/html \
--localstatedir=/var/nagios \
--with-htmurl=/nagios \
--with-cgiurl=/nagios/cgi-bin
[tyge@hven nagios-2.0]$ make all
[tyge@hven nagios-2.0]$ mkdir -p /var/www/nagios/html
[tyge@hven nagios-2.0]$ su -c "make fullinstall"
nagios-plugins er en særskilt programpakke der skal downloades. Den indeholder alle de check-programmer Nagios-dæmonen skal bruge, og uden nagios-plugins virker Nagios slet ikke. Hent programpakken (Afsnit 12.2.5) og installer pakken som angivet herunder:
[tyge@hven ~]$ cd nagios-plugins-1.4.3
[tyge@hven nagios-plugins-1.4.3]$ ./configure \
--with-cgiurl=/var/www/nagios/cgi-bin
[tyge@hven nagios-plugins-1.4.3]$ make
[tyge@hven nagios-plugins-1.4.3]$ su -c "make install"
Med de mest basale programmer installeret, mangler der nu et færdigt opsat eksempel du kan bruge som udgangspunkt. Det er beskrevet i næste afsnit.
12.2.2. Konfiguration
Nu mangler der et færdigt opsat eksempel. Der følger en smule med nagios-pakken, men det er ikke helt nok til at komme i luften med. For at kunne bruge eksemplet der følger med Nagios, skal der rettes så mange ting at det mindst vil tage dig 6 timer at komme frem til mål. Hent defor den færdige pakke fra http://cvs.linuxbog.dk/admin/eksempler/etc-nagios.tar.gz og stil dig i roden af din disk og pak den ud. Filerne vil lægge sig i /etc/nagios. Filerne kan også hentes enkeltvis og browses på http://www.linuxbog.dk/admin/eksempler/etc/nagios/
Når filerne er pakket ud er det vigtigt at få sat password til brugeren nagios. Det er den bruger som skal kunne logge ind via web-siden. Du kan tilføje alle de brugere du har behov for. Det gøres med programmet htpasswd2 når det er Apache 2.0 du har installeret, ellers er det htpasswd. Gør som nedenstående eksempel:
[nagios@hven ~]$ cd /etc/nagios [nagios@hven nagios]$ htpasswd2 htpasswd.users nagios New password: Re-type new password: Updating password for user nagios
Når password til nagios-brugeren er sat kan Nagios-dæmonen startes, og den nye konfiguration til Apache webserveren kan loades.
[root@hven ~]# /etc/init.d/nagios start
Nu er Nagios dæmonen startet og indsamling af data er begyndt. Næste trin er så at kunne se de indsamlede data. Det forventes at du har Apache-webserveren installeret, og har nogenlunde styr på at administrerer den. Det nemmeste er hvis du vil tilgå Nagios via http://localhost/nagios for så kan du nøjes med at inkludere sample-config/httpd.conf der ligger i filstrukturen under source nagios-pakken. Bruger du Gentoo er det nemmest blot at kopiere filen ned i filnavnet /etc/apache2/modules.d/99_nagios.conf (eller brug et andet nummer der er lavere end 99). Ved andre Linux-distributioner er det nok nemmest at kopiere sample-config/httpd.conf til /etc/nagios/ og så gå ind i din httpd.conf der hører til Apache og i bunden skrive Include /etc/nagios/httpd.conf . Når den config-fil der hører til Nagios er blevet inkluderet, er det blot at få den loadet ind i Apache. Det gøre evt. med følgende kommando:
[root@hven ~]# /etc/init.d/apache reload
Nu kan du klikke dig ind på http://localhost/nagios/ og se status for den maskine som Nagios er installeret på. Klik på service detail. Måske er der nogle service-check der lige står til "Pending", men så vent lige et par minutter, så kommer status også for disse. Som udgangspunkt viser eksemplerne der hører til "Friheden til at vælge" status for localhost og cvs.sslug.dk . For at rette det, skal der rettes i konfigurationsfilerne der ligger i /etc/nagios/*.cfg . Da der skal rettes i flere filer, kan man jo være fræk at gøre det fra kommandolinjen. Hvis du fx vil rette localhost til hven.sslug.dk, og du vil rette ip-nummer fra 127.0.0.1 til 80.80.80.80, så kan det gøres med:
[nagios@hven ~]$ cd /etc/nagios [nagios@hven nagios]$ grep localhost *.cfg # her ser du hvilke filer det er [nagios@hven nagios]$ perl -i -pe 's/localhost/hven.sslug.dk/g' *.cfg [nagios@hven nagios]$ perl -i -pe 's/127.0.0.1/80.80.80.80/g' *.cfg
12.2.3. Ændre konfiguration
Inden du kaster dig over at tilrette konfigurationsfilerne manuelt med en editor, skal du vide at der er indtil flere forskellige tredjeparts systemer der er beregnet for konfiguration via en GUI. En del af dem er baseret på PHP og MySQL, og nedarver selvklart de relationer der i forvejen er imellem Nagios' konfigurationsfiler. Download tredjepartsprogrammerne fra Afsnit 12.2.5.
Som udgangspunkt er konfigurationen fordelt på flere filer ved at der er refereret til dem fra nagios.cfg . Nogle gange vil man finde det irreterende at skulle åbne flere filer for at lave en ændring, men så er muligheden at man kan samle det hele i en fil. Det der handler om host og service har man ofte fat i, så det kan være en fordel at have dem i samme fil. Den måde som filerne kommer som standard er følgende:
-
services.cfg indeholder alle de services der skal overvåges på alle maskiner. De services der overvåges i eksemplet her, er dem som de fleste vil forvente er startet.
-
hosts.cfg indeholder en liste over alle de maskiner der skal overvåges. Her i eksemplet er det kun localhost og cvs.sslug.dk der er sat op til at blive overvåget. Det er så meningen at du skal gå ind og lave en søg-og-erstat af de to hostnavne, og sætte dine egne navne ind.
-
hostgroups.cfg er listen på alle de grupper af maskiner du har. De fleste har nok så få maskiner at de kun har én gruppe, men det er nemt at lave en gruppe mere.
-
contacts.cfg er listen over de personer der skal have tilsendt en mail, når der er noget galt.
-
contactgroups.cfg indeholder listen af de grupper der skal have sendt en mail, når der er noget galt. Når en service fejler, så er det gruppen der sendes en mail til. Det gør det nemmere at administrerer mange brugere samtidigt.
-
servicegroups.cfg er ikke så vigtig at have med til at starte med. Den giver fx et godt overblik af alle webservere, men på alle maskiner.
-
checkcommands.cfg indeholder listen over alle de kommandoer man kan bruge til at checke med i Nagios.
-
nagios.cfg er hoved konfigurationsfilen. Det er typisk en man kun vil rette i under installation, eller hvis skal tilføje meget avancerede funktioner. Som udgangspunkt skal du nok ikke rette i denne.
De resterende konfigurationsfiler er til mere avanceret opsætning og er ikke beskrevet her.
En ting der er fælles for den måde konfigurationsfilerne er opbygget på i Nagios, er at man definere først en standardindstilling, som man så efterfølgende bruger som basis for de andre definitioner. Har man kun et ganske lille system, der kun overvåges af ganske få systemadministratore, så vil man nok kun definere en gruppe der får tilsendt mail når noget går galt. Her vil man så i filen /etc/nagios/services.cfg øverst definere en template/objektklasse der indeholder navnet på den gruppe der skal have en mail tilsendt. Det er "contact_groups" der får tilsendt mail. Det kunne se ud som nedenstående:
define service{
name generic-service # navn på definitionen
register 0 # angiver at det kun er en default
contact_groups admins # eksempel på noget der nedarves
... flere definitioner følger
}
Der vil typisk være flere definitioner end vist herover. Det er blot beskrevet minimalt her, for at forklare princippet. Det man nu kan gøre med "generic-service" definitionen er at bruge den i alle de services man skal have defineret.
define service{
use generic-service # nedarv fra definition
host_name foo.eksempel.dk # navn på host
service_description HTTP # navn på service
check_command check_http # kommando der tjekker service
}
Ved et bruge ovenstående princip, kan man så i mange tilfælde definere en service med kun fire konfigurationslinjer. Får man brug for enkelte undtagelser, kan man så blot skrive det ind ved den service. Som eksempel kunne man forestille sig at webadministratorerne også skulle havee at vide hvis der er noget galt med HTTP. Ved så at indskrive contact_groups igen, overskrives den forgående definition. I Nagios skrives lister adskilt med komma.
define service{
use generic-service # nedarv fra definition
host_name foo.eksempel.dk # navn på host
service_description HTTP # navn på service
check_command check_http # kommando der tjekker service
contact_groups admins,webmasters
}
En ting der er god at huske efter man har lavet om på konfigurationen, er lige at køre et check om det man har lavet nu er rigtigt. Det gøres med kommandoen:
[tyge@hven ~]$ /usr/bin/nagios -v /etc/nagios/nagios.cfg
Herfter får man listet alle de fejl der måtte være og man kan gå igang med at rette dem.
Er der en check-kommando der driller, kan man altid prøve dem af fra kommandolinjen. En af de check-kommandoer der kan give underlige svar, er fx check_http_string. Den bruges til at undersøge om en hjemmeside indeholder en bestemt tekst. Det kunne være en tekst far en database, eller andet der indikere at mange af de services der skal fungere på en hjemmeside, er til stede. For at vide hvad programmet rigtigt hedder, må det findes i /etc/nagios/checkcommands.cfg og finde check_http_string. Her kan man se at programmet blot er check_http med en ekstra option. Definitionen ser således ud:
# 'check_http_string' command definition
define command{
command_name check_http_string
command_line $USER1$/check_http -H $ARG1$ -w $ARG2$ -c $ARG3$ -s "$ARG4$"
}
Hjælp til brug af check-kommandoerne fås alle ved option '-h'. '-s' bruges til at undersøge om en bestemt tekst forekommer. Nogle hjemmesider checker for hvilket sprog brugeren foretrækker, og her vil check-kommandoen spørge som default sprog, hvilket typisk er engelsk. Hvis man checker hjemmesiden med en browser, står der måske "Velkommen", men med check_http vil der stå "Welcome". På skærmen kunne det se således ud:
[tyge@hven ~]$ cd /usr/libexec/nagios [tyge@hven /usr/libexec/nagios]$ ./check_http -H www.eksempel.dk -w 5 -c 10 -s "Velkommen" HTTP CRITICAL: string not found|time= 0.020 [tyge@hven /usr/libexec/nagios]$ ./check_http -H www.eksempel.dk -w 5 -c 10 -s "Welcome" HTTP ok: HTTP/1.1 200 OK - 0.020 second response time |time= 0.020
12.2.3.1. services.cfg
Alle services der skal holdes øje med findes i services.cfg . Med services forstås fx en HTTP web-service. Her er det at der bliver testet om det kan lade sig at hente en hjemmeside, og samtidigt bliv er det noteret hvor lang tid det tog. I nedenstående anvendes direktivet use generic-service, hvilket så gør at alle de sædvanlige direktiver er nedarvet fra denne. Derved kan man nøjes med kun at angive fire linjer parametre for hver service der skal holdes øje med.
define service{
use generic-service
host_name localhost
service_description HTTP
check_command check_http
}
Har man en bestemt service man altid gerne vil bruger på alle de hosts man har defineret i hosts.cfg, så kan man fordel bruge en '*' som host_name. Eksempelvis kunne det være at alle skulle have en ping:
define service{
use generic-service
host_name * ; Alle hosts får en ping
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
12.2.3.2. hosts.cfg
De maskiner der skal overvåges er angivet i hosts.cfg. Som med services anvendes også her en standardkonfiguration benævnt use generic-host så alle fælles direktiver kan angives et sted. Det kan virke overflødigt at IP-adressen skal med, men som angivet i Nagios-manualen kan man komme ud for at DNS-serveren er nede, og så mister man overvågning af alle sine maskiner på én gang.
define host{
use generic-host
host_name localhost
alias Local Host
address 127.0.0.1
}
Til hver host kan der tilføjes ekstra information som ikke er påkrævet, men praktisk at have. Har fx en hel hjemmeside der beskriver hver enkelt maskine, kan sætte et link op til denne så man hurtigt kan klikke sig frem til informationen direkte fra Nagios overvågningssiden. Informationen kunne være som følger:
define hostextinfo{
host_name localhost
notes Den lokale vaert som Nagios er installeret paa
notes_url http://localhost/info.html
icon_image localhost.png # placeres i "/var/www/nagios/htdocs/share/images/logos"
icon_image_alt Lokal vaert
}
Som tidligere nævnt er der noget rod omkring hvor de forskellige filer skal ligge, og disse "icon_image" skal ligge i et subdir der hedder noget med "share/images/logos", og det må du så lede efter.
Her i eksemplet er brugt hostnavnet 'localhost', men det bør man ikke bruge i praksis, da det er forvirende hvis rent faktisk sidder ved en anden maskine.
12.2.3.3. hostgroups.cfg
På Nagios web-status-siden er der i venstre side en menu, hvor man kan vælge at se status på forskellig måde. En måde er at se de forskellige maskiner sammen som en gruppe, og så have flere grupper med et antal maskiner i. Er man flere personer om at overvåge maskiner, og hver har et ansvarsområde for et antal maskiner, kan man med fordel dele dem op i flere hostgrupper. Det fx være en gruppe med Linux-maskiner, og en med UNIX-maskiner. Gruppen kan også være den fysiske lokation såsom København og Ruds Vedby.
Man kan godt have den samme maskine nævnt i flere grupper samtidigt, men når der så er en fejl på den maskine vil der være to røde felter på skærmen, og på afstand vil det se ud som om der er to fejl. Så nævn kun hver maskine én gang i hostgroup-filen.
define hostgroup{
hostgroup_name gruppenavn ; Vælg et kort unikt navn
alias Langt navn for gruppen
members localhost, cvs.sslug.dk ; Kommasepareret liste
}
12.2.3.4. contacts.cfg
De brugere der skal have en meddelelse når der er noget galt med en maskine, skrives i listen contacts.cfg. I eksemplet der følger med beskrivelsen her, bruges en contact-template og så er det kun ganske få linjer man typisk skal skrive om hver person.
define contact{
use generic-contact ; Den definerede contact-template
contact_name nagios
alias Nagios Bruger
email nagios@localhost
}
12.2.3.5. contactgroups.cfg
Der vil ofte være flere personer der skal sendt en e-mail når noget går galt. Derfor definere man et antal personer i en gruppe, og ved de enkelte services angives hvilken kontaktgruppe der skal have besked når der er noget galt. Man kunne fx foresille sig at man i services.cfg havde en overvågning af web-servere (check_http) og her ville sende en mail til gruppen "webmasters" hvis der skete noget der. I det vedlagte eksempel er dog blot defineret en enkelt gruppe der modtager alle fejl, hvilket typisk vil være det de fleste har brug for.
define contactgroup{
contactgroup_name admins
alias Administrators
members root, nagios
}
12.2.3.6. servicegroups.cfg
Servicegrupper bruges til at overvåge en bestemt service, men på tværs af hvilke maskiner de køre på. I det viste eksempel er det webservices der bliver holdt øje med, og det gør så at man kan få en pæn liste op på skærmen der ikke viser andet end webservere. Bemærk her at listen af "members" skrives både med hostnavn og servicebeskrivelse: members <host_name>,<service_description> . Alle <host_name> og <service_description> kan findes i filen services.cfg , og man kan fx lave en hurtig liste til skærmen med kommandoen:
[tyge@hven nagios]$ egrep "(host_name|service_description)" services.cfg
Herunder et eksempel:
define servicegroup{
servicegroup_name HTTP
alias HyperText Transport Protocol
members localhost,HTTP, cvs.sslug.dk,HTTP
}
12.2.3.7. checkcommands.cfg
checkcommands.cfg indeholder definitionen på alle de check-kommandoer man kan kalde i services.cfg . Nogle af kommandoerne skal have parametre med såsom hostname, og andre skal ikke have nogen parametre. En nem måde at lære hvordan de enkelte check-programmer virker og hvordan de giver output, er at kalde dem fra kommandolinjen. Hvis du fx 48% diskplads tilbage på din rod-partition, så prøv at lave en warning på 50%. Nagios-plugins (hjælpe-programmerne) ligger i /usr/libexec/nagios, så prøv denne:
[tyge@hven ~]$ cd /usr/libexec/nagios [tyge@hven libexec]$ ./check_disk -w 50% -c 25% -p / DISK WARNING - free space: / 134354 MB (48%);| /=147041MB;140697;211046;0;281395
I stedet for at bruge mount-pointet '/' kan man også bruge selve devicen såsom '/dev/hda1', hvis det giver mere mening. De anvendte mount-point kan læses i /etc/mtab . Som det ses herunder hedder kommandoen check_local_disk.
define command{
command_name check_local_disk
command_line $USER1$/check_disk -w $ARG1$ -c $ARG2$ -p $ARG3$
}
Når man har fundet ud af hvilke parametre man til henholdsvis warning og critical, kan man oprette en definition i services.cfg:
define service{
use generic-service
host_name localhost
service_description Disk / mount
check_command check_local_disk!50%!25%!/
}
For alle check-programmerne gælder at man kalder dem med kommandoen -h for at få den fulde hjælp. Her får man så al den hjælp der findes, da reglerne for skrivning af plugins foreskriver at det skal være sådan.
12.2.3.8. nagios.cfg
Der er mange ting der kan ændres i hovedkonfiguratiosfilen nagios.cfg, men det vil oftest ikke være nødvendigt. Der kan være en enkelt path der skal ændres, men ellers er standardparametrene sat fornuftigt, og det er kun de andre filer man skal koncentrere sig om.
12.2.4. Manualen
Det er ikke mange steder i denne bog "Friheden til at vælge" hvor der er en beskrivelse af hvordan læser den engelsksprogede manual. Hvad angår Nagios, så er det påkrævet da den ikke er helt nem at finde rundt i. Der er desværre heller ikke noget stiksordsregister, hvilket kunne have hjulpet en del.
Links ændre sig hele tiden for den sidst gældende manual, men her er så alligevel et link til Nagios version 2.0 manual . Et emne, hvor det kunne være rart hvis det var nemt at finde, er der hvor der står noget om hvordan man definere services. Når der ikke lige er et stikordsregister, så er det lige sin sag at finde ud af at det er Table of Contents - > Configuring Nagios -> Object configuration file options -> Click here -> Service definitions man skal klikke på. Måske du bare skulle overvej at hente hele manualen hjem, så kan du altid bruge grep hvis der er noget du vil finde. Og nu du har hentet manualen hjem på egen harddisk, så kan du lige sætte fontene til noget lidt større så det er til at læse. 7 og 8 pt er lige lovlig småt når man bruger "serif". De to følgende kommandoer skulle klare de værste problemer.
[tyge@hven ~]$ wget -mk http://nagios.sourceforge.net/docs/2_0/
[tyge@hven ~]$ ls *.html | \
xargs perl -i -pe 's/font-size: [1-9]pt/font-size: 10pt/g'
12.2.5. Links
-
nagios.org er hjemmesiden for Nagios. Her downloades hovedprogrammet til indsamling af data og programmet til præsentation på web.
-
nagiosplug.sourceforge.net er hjemmesiden for check-programmerne for Nagios. Uden check-programmerne kan Nagios intet, så man skal downloade en pakke nagios-plugins.*.tra.gz her fra.
-
nagiosexchange.org indeholder alt muligt andet omkring Nagios. Der er forskellige programmer der gør det nemmere at sætte Nagios op, pakker med ikoner, og andre tillægsting til Nagios. Der findes flere pakker der handler om at gøre opsætning af Nagios nemmere, så det kan være interessant at kigge på den på et tidligt tidspunkt.